 Italiano
Italiano 

SMX London 2015, My Presentation on Schema
SMX London 2015 was a great conference! It was a pleasure to be back and speak before so many people about Schemas and how to use schema.org.
Already during the first day there was a considerable amount of talk about using Schema for SEO, I anticipated curiosity and expectations from our panel …
Here is my presentation I entitled:
From Documents & Data to Information & Entities
How to take your website to a new level with schema markup
The presentation delves into the details of how to implement Schemas using schema.org, but before doing so, it’s important to review the fundamental aspects and definitions of data and information.
An interesting paper written in 1986, Organizational Information Requirements, Media Richness and structural Design answers the question:
why do organizations process information?
Uncertainty and equivocality are defined as two forces that influence information processing in organizations.
These two forces are at work online today and are a major challenge to the search engines seeking to understand what our content is actually about.
Data is an array of values, and remains such until the right people with the right skills and qualifications and sufficient experience interpret the data, offering insights and actionable TO DOs.
Information shall be:
- Available
- Consistent
- Unambiguous
- Reliable
In addition to these requirements information also requires context, various attributes which characterize the subject:
- Properties (person, animal, or thing)
- Characteristics (dimensions, weight, name, … )
- Features (aspect, peculiarities, … )
- Location(Continent, Country, City … )
When the requirements and attributes are neatly assembled and organized, information becomes an entity – with schema we can bring our websites to a new level by implementing an additional layer of code, providing structure and attributes.
There are types (or “classes”) for virtually every existing business vertical. A full list is available at:
http://schema.org/docs/full.html
Why Use Structured Data?
On the schema .org website it is stated:
Your web pages have an underlying meaning that people understand when they read the web pages. But search engines have a limited understanding of what is being discussed on those pages. By adding additional tags to the HTML of your web pages … you can help search engines and other applications better understand your content and display it in a useful, relevant way.
The additional information we need to provide the search engines is implemented with:
- Itemscope
- Itemtype
- Itemprop
Itemscope
To begin, you need to identify the section of the page that is about something. To do this, add the itemscope element to the HTML tag that encloses information about the item, like this:

(This is the example I have taken from the schema.org website so you have a reference point on the site).
By adding itemscope, we are specifying that the HTML contained in the DIV block is about a particular item.
But it’s not all that helpful to specify an item is being discussed without specifying what kind of an item it is. We can specify the type of item using the itemtype attribute immediately after the itemscope.
So the markup then becomes:
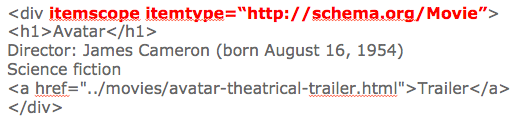
We can provide the search engines with additional information: Movies have properties such as actors, director, ratings. The itemprop attribute is used, for example, to identify the director of a movie, and the URL of the trailer…

The Property director has an expected type Person, so we can further elaborate our schema in this example and provide more signals about the director of the movie, which is of course a person with a:
- date of birth
- family name
- given name
All properties which we can include into the existing HTML considering the appropriate nesting of the elements: not separate entities, but attributes of the same item (entity). In this case the HTML code becomes:

This is a very important aspect to consider when implementing schemas: functional ties between properties are important and should be decided by management and the marketing team before any development is undertaken by internal or external IT experts.
You will have noticed how we included a meta tag in the body of the page to provide exact (unambiguous) information on the date of birth of the movie director. This is an unusual approach and at the schema.org website it is stated:
Sometimes, a web page has information that would be valuable to mark up, but the information can’t be marked up because of the way it appears on the page. This technique should be used sparingly. Only use meta with content for information that cannot otherwise be marked up
In reality the number of properties we can offer the search engines to reduce ambiguity and increase their confidence and understanding about our content is far greater than a few lines of meta data: search engines cannot understand context (not yet at least).
If we put the considerable amount of properties made available to work, we can describe a beautiful wedding photo, or a document, the amount of additional meta tags needed can quickly run into the hundreds of lines.
This will have a considerable impact on rendering and create additional work for the editorial staff.
At the moment a very small number of websites have implemented schema moving beyond the basic markup required to feature a page in the SERPS with a rich snippet.
It is my belief that the move to recommend JSON LD is an attempt to solve these issues and free content rendering of this additional layer of code which is difficult (almost impossible) to implement on a wide scale and in an automated fashion.
JSON LD offers significant advantages in this respect and is without doubt the best practise.
Schema is not an IT issue, it is a strategic business issue which must be addressed at management level. The preliminary model should be created by the marketing staff who can use the META TAGS option. Once the business model has been created and consolidated it can be implemented using JSON LD.
This is an Ongoing process
This is not a one time setup and configuration effort: your organization grows and changes and schema evolves – you need to reflect the evolution of both.
Need more information and assistance with your schema efforts?